

同样的算力与数据,为何有的模型就是跑得更好?
3月16日,

这一进展迅速在硅谷 AI 圈引发热议,社交媒体上有人直言这是“令人印象深刻的工作(Impressive work from Kimi)”。
Jerry Tworek(OpenAI o1 主要发明者): 认为这或许是“深度学习2.0”的开端。
Andrej Karpathy(前 OpenAI 联合创始人): 感叹行业对 “Attention is All You Need” 的理解还有很大挖掘空间。
为什么要动“祖传地基”?
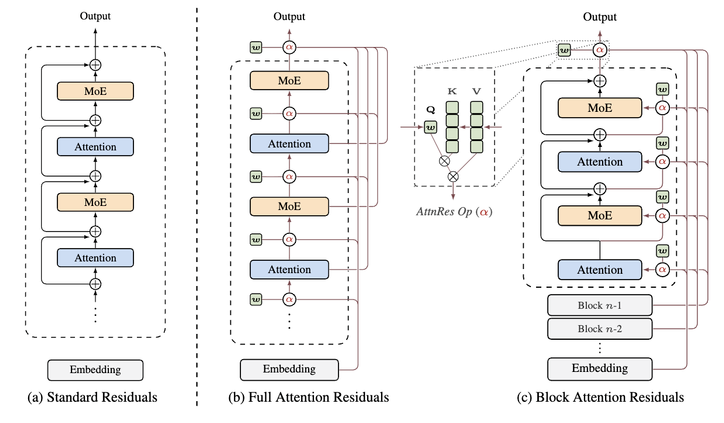
传统残差连接解决了深层网络难训练的问题,但“等权相加”的方式太粗糙。随着网络变深,每一层的新信息很容易被累积的旧信息淹没,结果就是不少中间层变成“低效劳动者”。

Kimi 的“优雅旋转”:
通过 Attention Residuals(AttnRes),每一层不再被动叠加上前面的输出,而是用一个小小的“查询向量”,主动、按需地从更早的层里挑选并提取信息。为控制大规模训练的内存与延迟,团队还提出了 Block AttnRes:把网络切成若干块,在基本不损伤效果的前提下,把推理时延的增幅压到2%以内。

在多项预训练与下游评测中,这一架构展现了出色的泛化能力:在 GPQA-Diamond 科学推理上取得了+7.5%的提升,数学与代码生成任务分别带来+3.6%和+3.1%的收益。

正如创始人在 GTC2026 的演讲中所说,行业正在遇到 Scaling 的瓶颈,必须对优化器、残差连接等底层基石重新设计。当多数人还在做“高层精装修”时,

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?