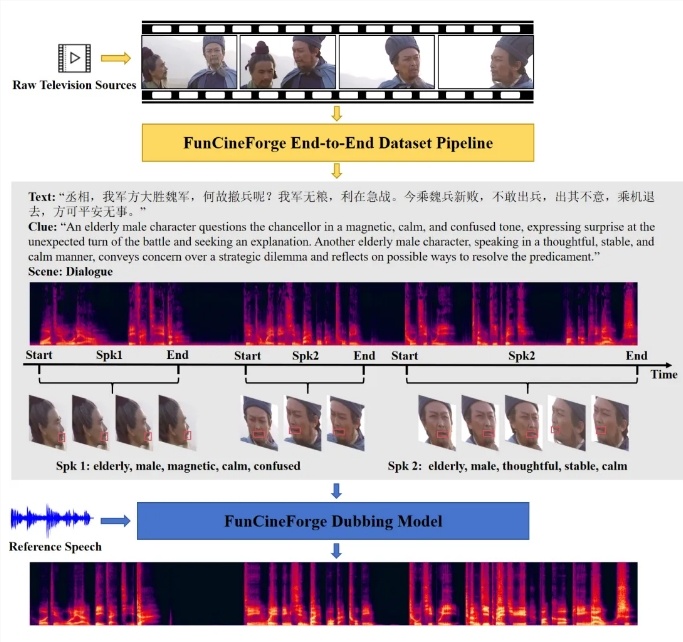


在影视、动画等高要求场景中,传统 AI 配音因难以精准还原强烈情绪与准确口型而频频受限。为解决这一痛点,通义实验室正式推出并开源了面向影视级多场景的多模态配音大模型——
攻克“声画脱节”:四个关键维度协同发力
有别于仅依赖文字转语音的传统方案,Fun-CineForge 瞄准影视制作中的四项核心难题:
-
口型同步: 让合成语音与画面中的唇部运动高度贴合。
-
情绪表达: 结合面部表情与指令描述,让声音更具情感层次与拟人化质感。
-
音色一致性: 在多角色复杂对话中,保持指定角色的音色稳定不偏离。
-
时间对齐: 即使说话者被遮挡或不在画面里,也能在毫秒级的准确时间点切入声音。
核心技术:引入“时间模态”与高质量数据集
Fun-CineForge 的关键突破在于其独特的 “数据+模型”一体化设计:

-
CineDub 高质量数据集: 通义实验室同步开源了 CineDub 自动化数据集构建流程。该流程通过链式思维纠错机制,将中英文文本转录错误率降至约 1% -2%,说话人分离错误率显著降至约 1.2%。
-
四模态融合架构: 模型首次引入 “时间模态”,并与视觉(唇形与表情)、文本(台词与情感)和音频(音色参考)联合建模。由此,即便在“看不到”人脸的复杂镜头中,也能依靠时间监督目标实现精准同步。
表现出色:补齐多人对话配音空白
实验结果显示,Fun-CineForge 在词错率(WER/CER)、唇部同步度(LSE-C/D)以及音色相似度等指标上,均显著优于 DeepDubber-V1 等基线模型。尤其值得注意的是,模型首次实现了对双人及多人对话场景的精准支持,在 30 秒以内的视频片段中展现出很强的稳定性与鲁棒性。
-
GitHub:https://github.com/FunAudioLLM/FunCineForge
-
HuggingFace:https://huggingface.co/FunAudioLLM/Fun-CineForge
-
ModelScope:https://www.modelscope.cn/models/FunAudioLLM/Fun-CineForge/

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?