

当各大 AI 厂商一味加料、厮杀跑分巅峰之时,马斯克旗下 xAI 选择换个思路,直面模型“一本正经瞎编”的老问题。今天,xAI 正式发布 Grok4.20Beta。即便在绝对智力榜单上与顶级队伍尚有差距,但它在“诚实度”这一关键维度上,直接刷新了行业纪录。

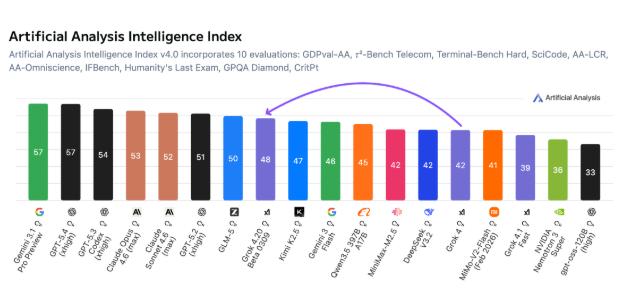
按照 Artificial Analysis 的最新测试,Grok4.20 在推理模式下的智力指数拿到 48 分,低于
-
最低幻觉率:在 AA Omniscience 测试中,Grok4.20 实现了 78% 的“非幻觉率”,创下迄今为止的最高纪录。
-
知之为知之:面对无从作答的问题,模型不再习惯性“编细节”,而是更倾向于直接承认“不知道”。这种“坦诚”对严肃办公与研究场景尤为关键。
技术架构:三管齐下的 API 组合
为覆盖不同层级与场景,xAI 同步推出三类 API:
推理模式(Reasoning):以牺牲速度换取更深入的逻辑思考,是本次降低幻觉的核心所在。
标准模式(Non-reasoning):面向日常对话与高效响应。
多智能体模式(Multi-agent):支持多实例协作,处理更复杂的任务链。
市场策略:更高配同价位
在产品力之外,Grok4.20 的商业策略同样激进:
-
海量上下文:支持最高 200万 token 的上下文窗口,可一次吞下整本书或大规模代码库。
-
价格优势:定价为每百万 token 2 至 6 美元,不仅比前代 Grok4 更亲民,也在当前西方主流模型中极具竞争力。
Grok4.20 的推出,意味着 xAI 的路线有所调整——不再一味追逐通往 AGI 的总分排名,而是精准切入“企业级可靠性”的核心痛点。正如测评机构所言,若其他模型致力于当“无所不知的先知”,那 Grok4.20 则努力扮演“绝不编造的助手”。
对于那些对数据准确性要求极高的用户而言,Grok4.20 有望成为 OpenAI 和谷歌之外的第三个重量级选择。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?