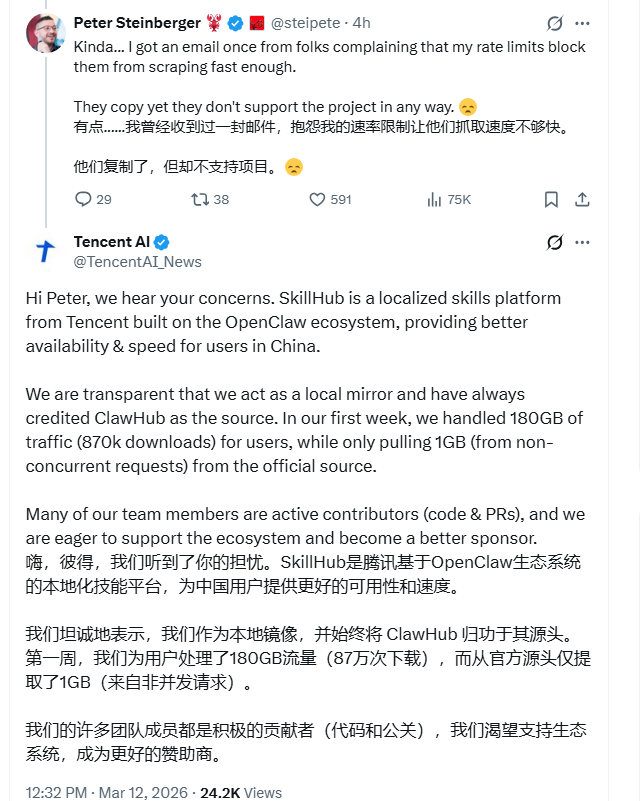


近期,热门智能体项目 OpenClaw 的开发者 Peter Steinberger 在社交平台 X 上公开指称,腾讯未经许可抓取了其 ClawHub 平台上的全部技能数据,用于搭建自家的「SkillHub」。
Steinberger 表示,腾讯在未对原项目提供实际支持的情况下进行了整库复制,甚至有相关人员曾发邮件抱怨 ClawHub 的“访问限速”影响了抓取效率。

针对上述说法,腾讯 AI 官方账号随即回应称,SkillHub 的初衷是基于 OpenClaw 生态做一个面向国内的本地化技能镜像平台,目的是解决中国用户访问延迟等可用性问题。腾讯披露的技术数据称,SkillHub 上线首周已处理 180GB 流量(约 87 万次下载),而实际仅从官方源拉取了 1GB 数据,客观上为原站分担了 99.4% 的带宽压力。
另外,腾讯强调其团队成员一直是该项目的活跃贡献者,后续也愿以赞助等方式深化合作。尽管有人认为镜像站能显著降低开源项目的运营成本,但 Steinberger 坚持认为,尊重开源协议与开发者的知情权是合作前提,双方应在同步沟通的基础上达成官方认证,而不是单方面镜像。
这场风波折射出,在大模型与智能体应用加速落地的当下,开发者原创权益与大厂生态扩张之间的博弈。如何在追求效率的同时,建立更有“礼貌”和更透明的开源协作机制,仍是 AI 行业需要持续探索的课题。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?