

研究机构 METR 最新公布的一项研究指出,常用于评估 AI 编程水平的基准 SWE-bench Verified,可能明显高估了 AI 代理在真实软件开发中的表现。团队发现,基准中被判定为“通过”的 AI 方案里,约有一半在实际项目维护者复核时会被否决,这说明自动化评测与真实工程质量之间存在不小的差距。
SWE-bench Verified 一直被当作 AI 辅助软件工程的重要参考之一,用来检验模型能否解决开源项目中的真实问题,并通过自动化测试来确认代码改动能否通过项目用例。包括 Anthropic 和 OpenAI 在内的多家 AI 公司也常以该基准成绩展示模型能力进展。

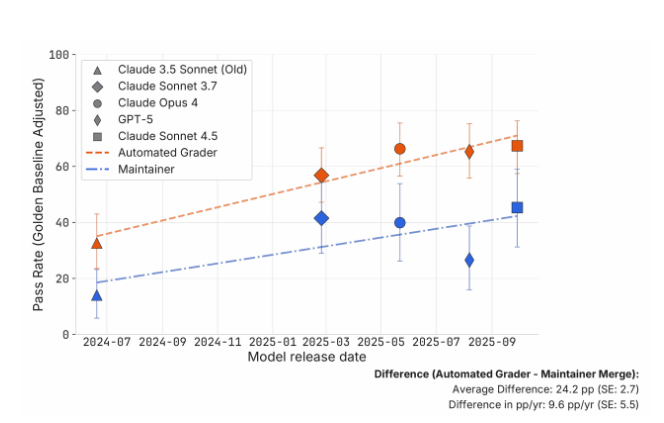
在本次研究中,METR 邀请了负责开源项目 scikit-learn、Sphinx 与 pytest 的四位资深维护者,对 296 段 AI 生成的修复代码进行人工审查。这些提交来自五个模型的方案,包括 Claude3.5Sonnet、Claude3.7Sonnet、Claude4Opus、Claude4.5Sonnet 以及 GPT-5。结果显示,按维护者的实际采纳率,平均比 SWE-bench 的自动评分低约 24 个百分点,这一差异具有统计学显著性。
研究还发现,被否决的 AI 代码并非主要因为风格或格式问题,而是存在更实质的工程缺陷。维护者将问题归纳为三类:代码质量不符项目规范、破坏既有代码结构,以及功能性错误。其中不少案例属于功能层面的失效——即使自动测试通过,代码也没有真正修好问题。
在模型对比方面,研究看到:从 Claude3.5Sonnet 升至 Claude3.7Sonnet,尽管基准“通过率”显著提高,但被维护者标注的功能性错误也增多;从 Claude3.7 到 Claude4Opus,问题重心更多转向代码质量;而 Claude4.5Sonnet 在代码质量上有所改进。相较之下,GPT-5 在本次评估中的整体表现明显落后于 Anthropic 系列模型。
")
研究团队还对“任务所需时间”进行了估算:按 SWE-bench 的自动评估推算,Claude4.5Sonnet 达到 50% 成功率的任务需要约 50 分钟的人力;但按维护者评分折算仅约 8 分钟。由此推断,基准可能将能力高估了最高约 7 倍。
不过研究者也强调,这并不意味着 AI 编程代理的能力已触顶。通过更好的提示策略、更多人工反馈或开展多轮迭代,自动评测与人工审核之间的差距仍有望缩小。此外,实验设置与真实开发流程并不完全一致,例如 AI 代理只给出一次提交,而人类开发者通常可以根据反馈反复修改。
总体来看,单靠基准分数来衡量 AI 编程代理的实际效用,可能会带来系统性偏差。随着 AI 编码模型快速迭代,如何构建更贴近真实开发场景的评测体系,正成为 AI 软件工程领域的重要研究方向。

















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?