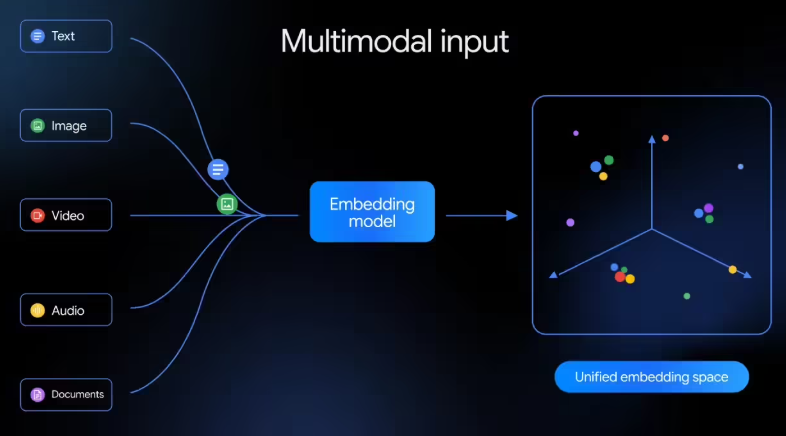


谷歌面向公众发布全新的 Gemini Embedding 2。作为谷歌首款原生多模态嵌入模型,它突破了传统只能处理单一数据形态的限制,能够把文本、图片、视频、音频以及文档共同映射到同一个向量空间,从而实现跨媒介的深度理解。
与主打内容生成的 Gemini 3 等生成式模型不同,嵌入模型的核心任务是“理解”。它把复杂信息转成机器可用的向量表示,帮助系统捕捉语义联系,在搜索准确度与上下文关联上远超基于关键词的检索方式。

Gemini Embedding 2 的核心特性与亮点:
-
多模态全覆盖:不仅支持文本,还可直接处理 PNG/JPEG 图片、最长 120 秒的 MP4/MOV 视频、原生音频数据,以及最多 6 页的 PDF 文档。
-
面向全球的语言理解:可在多达 100 种语言中准确把握用户的语义需求。
-
跨媒介联合分析:一次请求即可输入“图像 + 文本”等组合内容,深度挖掘不同媒介之间的内在联系。
-
丰富的落地场景:在检索增强生成(RAG)、语义搜索、情感分析与大规模聚类等任务上显著提升表现。
谷歌在官方博客举例称,在法律诉讼取证等复杂业务中,Gemini Embedding 2 能在海量、跨媒介的数据里迅速定位关键证据,大幅提升检索的精度与召回效果。目前,该模型已通过 Gemini API 与 Vertex AI 向公众开放预览。
对开发者而言,这次更新意味着可以更便捷地打造能处理真实世界复杂数据的 AI 应用,让机器不只是会“看”和“听”,更能理解不同信息背后的一致逻辑。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?