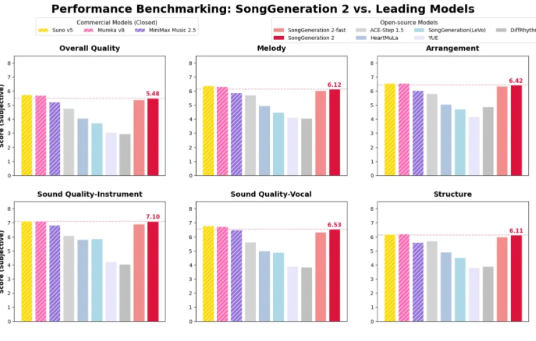


AI 音乐赛道在2026年初再次被重磅消息点燃。3月9日,由

三项关键升级:AI 音乐告别“塑料味”
-
音乐性更强: 不再只是简单拼旋律,它能胜任复杂多轨编配,空间层次清晰。
-
歌词对齐更准: 含糊咬字、跑调等问题明显缓解。其音素错误率(PER)仅 8.55%,这一数据显著优于顶级商业模型
Suno v5 MiniMax2.5 -
可控性更强: 无论是文字描述还是音频提示,都能精准执行,细致定制风格与情绪。

双引擎驱动:LLM 与扩散模型的强强联合
在系统设计方面,
-
作曲大脑(LeLM): 统筹全曲结构与演唱细节,回答“怎么唱”。
-
高保真渲染器(Diffusion): 在语言模型的指引下,合成丰富而复杂的声学细节。
-
分层表征: 首创混合表征与多轨表征并行建模,兼顾旋律稳定与音质细腻。
真开源、易上手:家用电脑也能“写歌”
更让开发者振奋的是,腾讯这次拿出了十足的开源诚意。拥有 4B 参数的
为便于快速体验,项目组还在 HuggingFace 上推出了
从

















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?