

随着 AI 大模型参数量不断冲向万亿级,支撑训练的 GPU 集群已经成为当今最复杂、也最容易出问题的计算系统。为了应对大规模训练中频繁出现的硬件不稳定情况,Meta AI 研究团队近日开源了 GCM(GPU Cluster Monitoring)工具套件。这不只是一次普通的技术放出,更像是 Meta 面向高性能计算(HPC)社区给出的一份 GPU 集群运维与管理实践方案。

在传统 Web 业务中,如果服务器响应慢了,通常可以通过简单的加机器、扩容来缓解。但在 AI 训练场景下,规则完全变了:在一个拥有成百上千张显卡的集群里,只要有一张 GPU 出现“静默故障”——看上去在线正常、实际上性能严重掉队——就像在训练过程中掺进“毒素”,会悄悄拖慢整体进度,甚至把好几个星期的训练成果全部毁掉。Meta 推出 GCM 的目的,就是要在底层硬件遥测数据和上层调度编排逻辑之间搭建一座专业又可靠的桥梁。
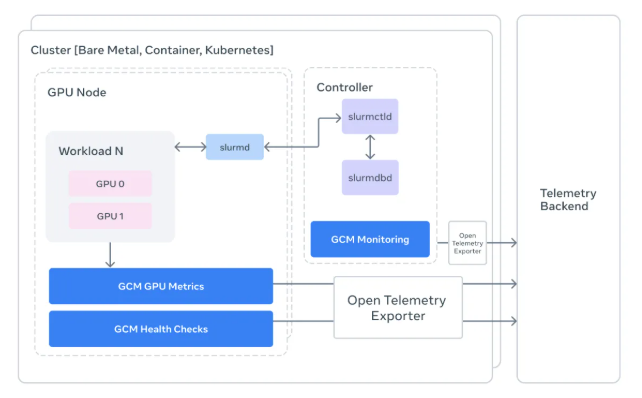
据了解,GCM 与业内广泛使用的任务调度系统 Slurm 做了深度集成。它可以把监控粒度细化到“任务级别”:工程师不再只看到含糊的功耗曲线波动,而是能直接追踪到具体是哪一个任务 ID 引发了性能异常。借助这张实时更新的集群“健康地图”,系统可以在研究人员察觉到问题之前,自动识别、标注并隔离存在风险的节点。
除了任务级监控,GCM 还加入了严格的“任务前后检查”流程。在作业启动前,它会先验证网络链路和 GPU 是否处于可用状态;在作业结束后,则调用 NVIDIA DCGM 进行更深入的硬件检测和分析。通过把复杂繁杂的底层指标统一转换成标准化的 OpenTelemetry 数据格式,GCM 让运维人员也能像看网站流量报表一样,在 Grafana 等看板上直观查看每块 GPU 的“健康体检结果”。
概要:
-
🔍 锁定隐形故障:专门针对表面在线、实则性能下滑的“僵尸 GPU 节点”,避免这类静默硬件问题悄然干扰训练过程、污染模型结果。
-
🛠️ 深度作业关联:与 Slurm 调度系统紧密集成,把功耗、错误日志等关键指标精确映射到具体任务 ID,方便快速定位和处理问题任务。
-
🩺 全程健康监测:通过任务启动前的可用性自检与任务结束后的自动体检,提前发现并剔除异常硬件,保证高价 GPU 资源用于“靠谱”的训练作业。

















用户38505528 10个月前0
粘贴不了啊用户12648782 11个月前0
用法杂不对呢?yfarer 11个月前0
草稿id无法下载,是什么问题?