

2月11日,蚂蚁集团发布并开源全模态大模型 Ming-flash-omni 2.0。多项公开基准显示,它在视觉-语言理解、可控语音生成,以及图像生成与编辑等核心能力上表现亮眼,部分评测数据超过 Gemini 2.5 Pro,堪称开源全模态模型的新标杆。
Ming-flash-omni 2.0 还是业内首个覆盖全场景的音频统一生成模型,能在同一音轨里同时产出语音、环境音与音乐。用户只需用自然语言指令,就能细致控制音色、语速、语调、音量、情绪、方言等参数。模型推理阶段达成了 3.1Hz 的超低帧率,支持分钟级长音频的实时高保真合成,在推理效率与成本上保持领先。

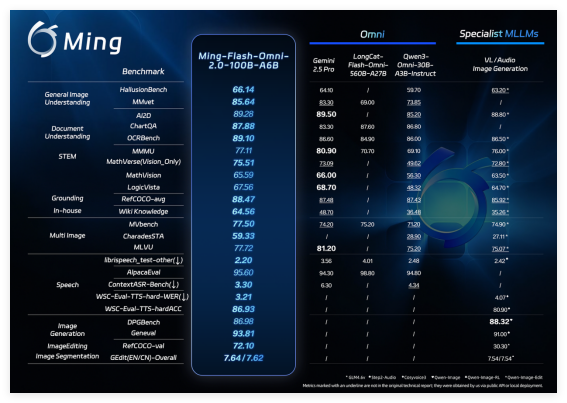
(图说:Ming-flash-omni 2.0 在视觉语言理解、可控语音生成、以及图像生成与编辑等方面的实测表现已处于开源领先水平)
行业普遍认为,多模态大模型终将走向统一架构,让不同模态与任务更好协同。但现实中,“全模态”模型常难以兼顾通用性与专精度:在某些单项上,开源方案仍弱于专用模型。蚂蚁集团多年深耕这一方向,Ming-omni 系列据此持续演进:早期版本打牢统一多模态能力底座,中期版本验证规模扩张带来的能力跃升,而最新 2.0 依托更大数据与系统化训练优化,把多模态理解与生成推至开源领先,并在部分领域超过顶级专用模型。
此次将 Ming-flash-omni 2.0 开源,意味着其核心能力以“可复用底座”的形式对外释放,为端到端多模态应用开发提供统一能力入口。
Ming-flash-omni 2.0 基于 Ling-2.0 架构(MoE,100B-A6B)训练,围绕“看得更准、听得更细、生成更稳”三大目标做了全面优化。视觉方面,融合亿级细粒度数据与难例训练策略,显著提升对近缘动植物、工艺细节和稀有文物等复杂对象的识别能力;音频方面,实现语音、音效、音乐同轨生成,支持用自然语言精细调控音色、语速、情绪等参数,并具备零样本音色克隆与定制能力;图像方面,增强复杂编辑的稳定性,支持光影调整、场景替换、人物姿态优化及一键修图等功能,在动态场景中也能保持画面连贯与细节真实。
百灵模型负责人周俊表示,全模态的关键在于用统一架构把多模态能力深度融合、高效调度。开源后,开发者可在同一框架内复用视觉、语音与生成能力,明显降低多模型串联的复杂度和成本。接下来,团队会继续强化视频时序理解、复杂图像编辑与长音频的实时生成,同时完善工具链和评测体系,推动全模态技术在业务场景中规模化落地。
目前,Ming-flash-omni 2.0 的模型权重与推理代码已在 Hugging Face 等开源社区上线,用户也可通过蚂蚁百灵官方平台 Ling Studio 在线体验与调用。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?