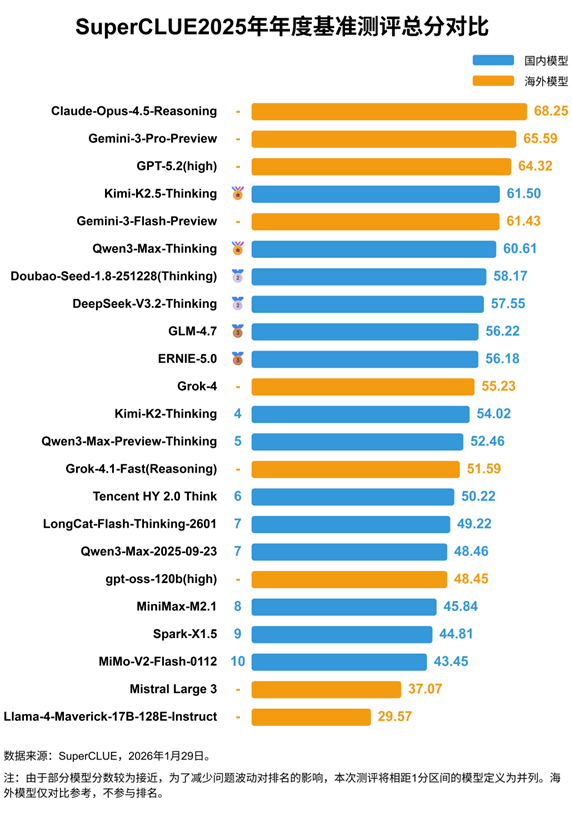


SuperCLUE发布了《2025年度中文大模型基准测评报告》。此次评测集结了海内外共23个顶尖模型,可谓一场“全明星”对决,进一步展现了全球AI格局的新趋势。评价维度涵盖数学推理、代码生成、科学推理等六大核心项,清晰呈现各模型在中文场景下的实际“战力”。

综合榜单显示,海外闭源模型仍然占据明显优势。Anthropic的Claude-Opus-4.5-Reasoning以68.25分拿下冠军,谷歌的Gemini-3-Pro-Preview和OpenAI的GPT-5.2(high)分列第二、第三。这三家巨头组成了“第一梯队”,在逻辑性与整体理解能力上继续保持小幅领先。
与此同时,国产大模型进步迅速,正在快步追赶。开源阵营中的“带头”选手Kimi-K2.5-Thinking与闭源代表Qwen3-Max-Thinking双双跻身全球前十,分别排名第4和第6。更亮眼的是,在细分赛道上已出现“局部超越”:Kimi在代码生成任务拿下全球第一,Qwen3则在数学推理上与谷歌并列第一。
从更大视角看,海内外的竞争路径明显不同:闭源赛道是“海外领跑、国产紧跟”;而在开源阵营,国产模型已占据绝对主导,国内开源Top5整体实力显著领先海外同类。这种“开闭并进”的格局,意味着中文AI生态正迈入高质量发展的加速期。
划重点:
-
🏆 海外巨头领跑: Claude-Opus-4.5-Reasoning以最高分登顶中文大模型榜,海外闭源模型继续包揽前三。
-
🚀 国产局部超越: Kimi-K2.5-Thinking在代码生成领域夺冠,Qwen3-Max-Thinking则在数学推理上与谷歌Gemini并列全球第一。
-
📊 开源国产主导: 开源阵营中,国产模型整体表现显著领先海外竞争者,体现出国内大模型在开放协作上的优势。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?