

智谱今日宣布上线并开源专业级 OCR 模型 GLM-OCR。这款模型仅有 0.9B 体量,却实现跨越式性能提升,在多项权威评测中名列前茅,专注解决复杂文档解析的真实业务难题。
核心能力:小体量也能跑出 SOTA
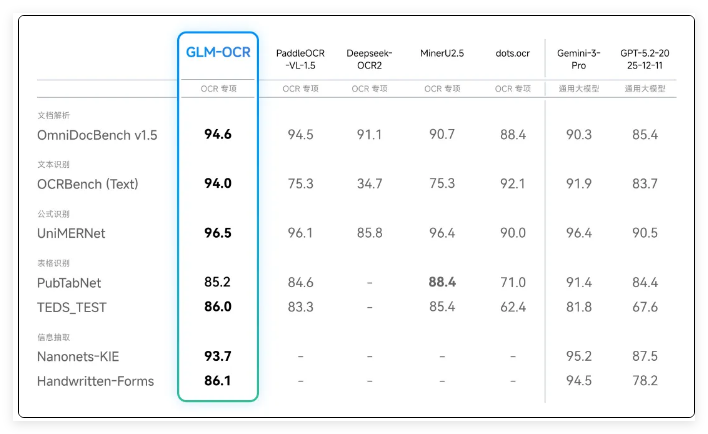
虽然参数规模只有 0.9B,GLM-OCR 的表现依旧亮眼。在权威文档解析榜单 OmniDocBench V1.5 上,以 94.6分摘得第一,实力接近通用大模型 Gemini-3-Pro。无论是文本识别、数学公式理解、复杂表格解析,还是关键信息抽取(KIE),都拿到 SOTA(业内最顶尖)成绩。

场景突破:聚焦复杂文档难点
GLM-OCR 围绕六大高难业务场景做了专项优化,表现稳定可靠:
-
复杂表格: 支持合并单元格与多级表头,可直接生成标准 HTML。
-
结构化提取: 智能识别各类卡证票据,输出符合规范的 JSON。
-
手写体与代码: 适配教育科研中的手写公式,以及程序员的代码截图。
-
特殊标识: 对印章识别和多语混排有极高鲁棒性。

极致效率:更快推理,更低成本
在性能与费用控制方面,GLM-OCR 具备强竞争力:
-
高速推理: PDF 处理吞吐可达 1.86页/秒,明显领先同类;兼容 vLLM、Ollama 等主流部署。
-
极致性价比: API 定价低至 0.2元/百万 Tokens。相较传统 OCR,成本仅为其十分之一,处理一千张 A4 扫描件约需 0.5 元。
技术解析:多模态架构结合强化学习
GLM-OCR 采用 GLM-V 系列多模态架构,集成自研 CogViT 视觉编码器。通过引入**多 Tokens 预测损失(MTP)**与全任务强化学习,模型在复杂版面下的泛化能力显著增强。其独特的 4 倍下采样策略与 SwiGLU 机制,让视觉信息与语言解码器高效协同。
目前,GLM-OCR 已在

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?