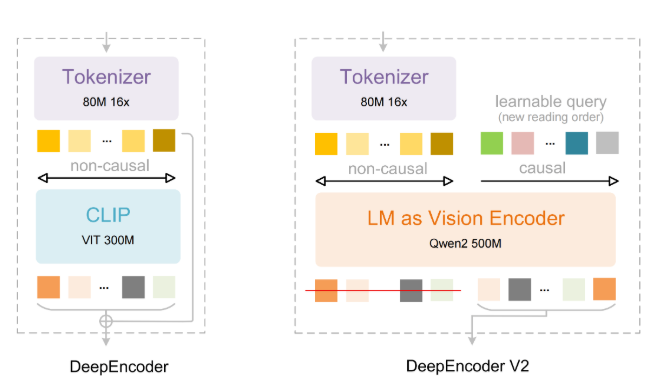


中国 AI 头部企业 DeepSeek 近日发布全新的视觉编码器 DeepSeek OCR2,在文档处理与图像识别领域取得重大进展。该模型模仿人类视觉的灵活扫视方式,打破传统视觉模型逐格平铺处理的旧逻辑。

DeepSeek 的研究人员表示,人眼在观察时会根据内容进行选择性聚焦。为实现这一点,DeepSeek OCR2 采用了全新架构,不再使用传统的 CLIP 组件,改为轻量语言模型式设计。该架构通过“因果流 Token”重新编排视觉信息并整合上下文,让 AI 更像人类一样,按内容意义而非固定网格顺序来“观察”世界。
这种创新的处理方式不仅提升理解力,还显著优化了效率。在相同图像任务中,DeepSeek OCR2 仅需 256 到 1,120 个 Token,而许多同类系统通常要消耗 6,000 个以上。其视觉 Token 用量减少超过 80%。这份极高的压缩率让模型在处理长文档时更省成本、更提速度。

在权威的 OmniDocBench 基准测试中,该模型以 91.09% 的成绩刷新纪录,在文档解析表现上全面超越 Gemini3Pro。目前,DeepSeek 已将该模型的代码与权重向公众开放。研究团队认为,这一架构是迈向统一多模态处理的重要一步,未来有望在同一框架下实现文本、语音与图像的深度融合理解。
划重点:
-
🚀 能效巅峰: DeepSeek OCR2 将单张图像的视觉 Token 需求大幅压缩,相比同类系统减少约 80% 的资源消耗。
-
📑 性能超越: 在 OmniDocBench 测试中,模型在文档解析与阅读顺序识别方面表现亮眼,准确率领先 Gemini3Pro。
-
🧠 架构创新: 借助“因果流 Token”重组视觉信息,模型从机械式扫描跨越到按内容逻辑进行理解。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?