

今日凌晨,智谱AI宣布开源其全新“混合思考”模型——GLM-4.7-Flash。作为30B规格中的强势选手,该模型在延续轻量化部署优势的同时,凭借出色的推理与编码能力,成功登上同类规格模型的性能榜首。

性能领跑:30B级别的“全能王牌”
GLM-4.7-Flash 采用了 30B-A3B MoE(混合专家)架构。也就是说,整体参数规模约300亿,但在实际任务中仅有约30亿关键参数被激活。这种设计在资源占用与处理能力之间找到理想平衡。
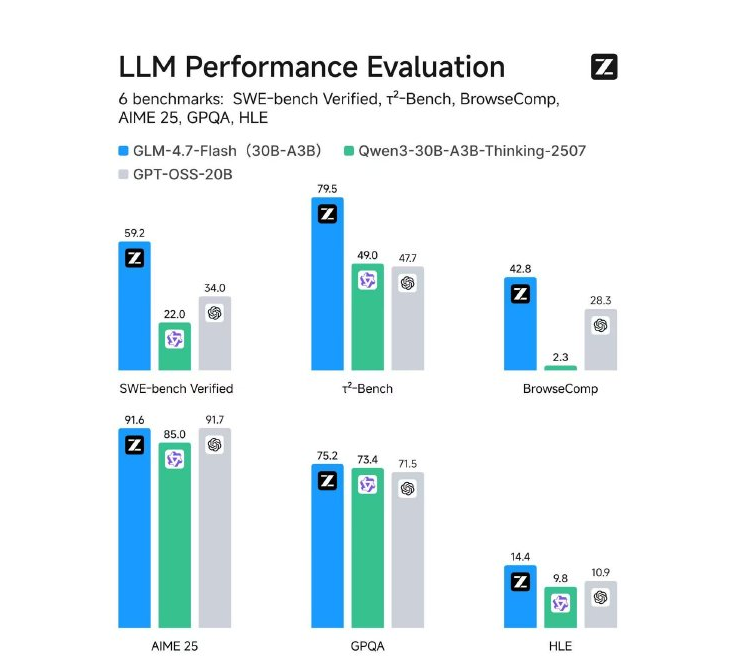
在多项严格的基准测试中,GLM-4.7-Flash 的表现相当亮眼,整体超越了阿里的 Qwen3-30B-A3B-Thinking-2507 以及 OpenAI 的 GPT-OSS-20B:
-
软件工程(SWE-bench Verified): 取得 59.2分,展现出强劲的代码修复实力。
-
数学与推理: AIME25拿下 91.6分,GPQA(专家级问答)达到 75.2分。
-
工具协作: τ²-Bench 得分 79.5分,BrowseComp 为 42.8分,在智能体(Agent)场景中竞争力十足。
开发者友好:灵活的本地化部署
该模型主打轻量与实用,尤其适合在本地或私有云环境中构建智能体应用。为保证性能稳定发挥,GLM-4.7-Flash 已获多种主流推理框架支持:
-
vLLM 与 SGLang: 均已在 main 分支提供支持。使用 vLLM 时可通过
tensor-parallel-size和speculative-config等参数提升并发与解码效率;SGLang 则支持使用 EAGLE 算法进一步加速推理。 -
Hugging Face: 可直接用
transformers库调用,便于快速实验与系统集成。
市场反馈:不牺牲轻便的性能跃迁
社区对该版本反响热烈。用户普遍认为,GLM-4.7-Flash 在不增加硬件负担的情况下,明显提升了实际任务中的“体感速度”。有开发者评价:“它在编码和工具调用上的表现,让本地AI助手真正好用。性能与效率的平衡,正是我们需要的。”
开源地址:https://huggingface.co/zai-org/GLM-4.7-Flash

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?