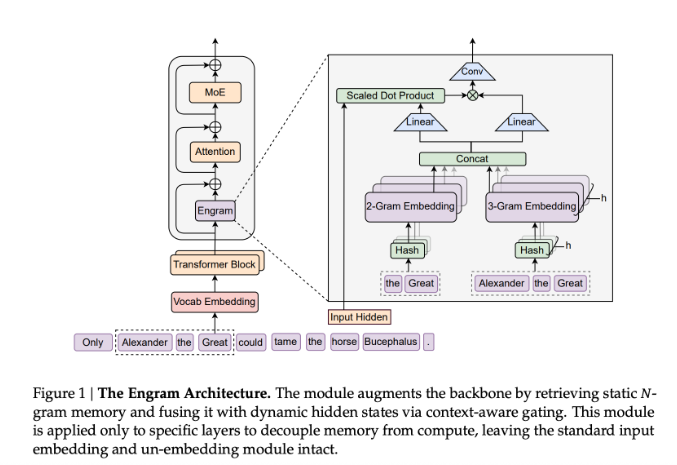


传统的 Transformer 在处理重复性知识时常常“重复计算”,遇到同样的模式也要从头来一遍,既拖慢网络深度又浪费算力。为破解这一瓶颈,DeepSeek 研究团队近期推出了名为 Engram 的创新模块,让稀疏大语言模型(LLM)拥有一条高效的“条件记忆轴”。

不同于现有的混合专家模型(MoE),Engram 并不是替代者,而是一个增强组件。它把经典的 N-gram 嵌入思路现代化,做成可扩展、查询复杂度为 $O(1)$ 的查找库。通俗来说,Engram 就像模型的“快捷记忆本”,专门存放常见短语、实体等静态模式,让骨干网络把精力留给更难的推理和长距离交互。
在实际应用中,
在长文本场景下,Engram 同样亮眼。将上下文窗口扩展到32,768个 token 后,Engram 模型在多查询“大海捞针”(NIAH)与变量跟踪等任务上准确率更高。这样的设计不仅增强了模型的知识储备与召回,还把静态重构任务分担出去,相当于变相提升了模型的有效深度,让 AI 更聪明、更高效。
划重点:
-
🧠 创新架构:
DeepSeek -
📈 性能飞跃: 在同等计算资源下,引入 Engram 的 27B 与 40B 模型在 MMLU、数学与代码等核心榜单上全面超越传统 MoE 架构。
-
📑 长文本增强: 该技术显著提升模型的长上下文召回能力,在 32k 长度的测试中表现优异,并有效降低预测所需的层间开销。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?