

近日,科技媒体 AppleInsider 报道,苹果发布了一篇重磅研究论文,介绍了最新研发的多模态 AI 模型 “zano”。该模型把“视觉理解”和“文本生成图像”两大能力融合在一起,被视为 AI 技术的又一次重要进展。
“Manzano”的最大亮点是它的“双修”本领:既能像人类一样准确读懂图片内容,也能依据文字生成高质量的图像。在业内,能同时做好这两件事的模型并不多见,很多现有方案常在画质与理解之间做取舍。

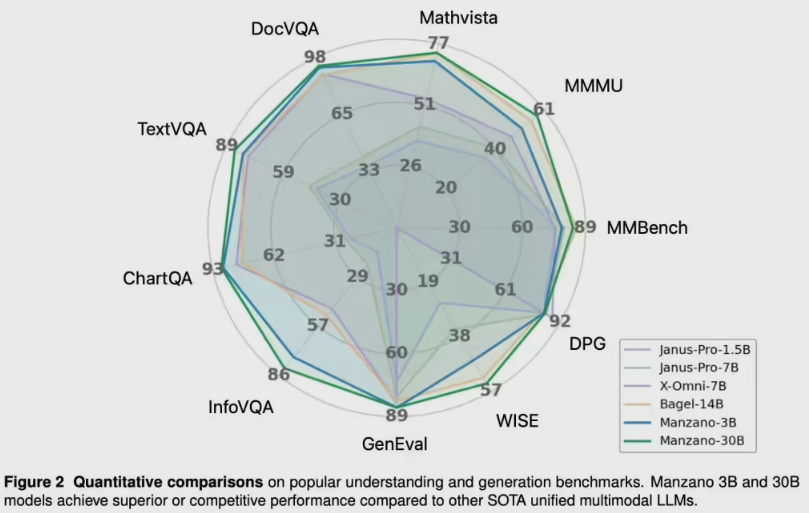
为了解决这一难题,Manzano 采用了三段式架构。首先引入一种“混合器”,可同时产生连续与离散的视觉表征;随后由强大的大语言模型(LLM)预测图像的语义内容;最后通过“扩散解码器”完成像素级生成。这个设计让 Manzano 在图像理解与生成方面都表现出色,甚至还能应对深度估计、风格迁移与图像修复等复杂任务。
数据显示,Manzano 在处理反直觉、违背物理常识的复杂指令时表现不俗。例如,当生成“一只鸟在大下方飞翔”的画面时,Manzano 的逻辑准确性与 OpenAI 的 GPT4o 和谷歌 Nano Banana 模型不相上下。研究团队也对不同参数规模的版本进行了测试,结果显示模型扩大后性能依然显著提升。
尽管目前 zano 仍处于研究阶段,尚未直接应用到 iPhone 或 Mac 设备,但这无疑体现了苹果在打造更强大底层能力方面的雄心。未来,业内普遍认为 Manzano 技术很可能融入苹果即将推出的“图乐园 Image Playground”功能,为用户提供更智能的修图体验和更具想象力的图像生成能力,从而进一步巩固苹果在端侧 AI 领域的竞争力。

© 版权声明
AI智能体所有文章,如无特殊说明或标注,均为本站作者原创发布。任何个人或组织,在未征得作者同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若此作者内容侵犯了原著者的合法权益,可联系客服处理。
THE END
















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?