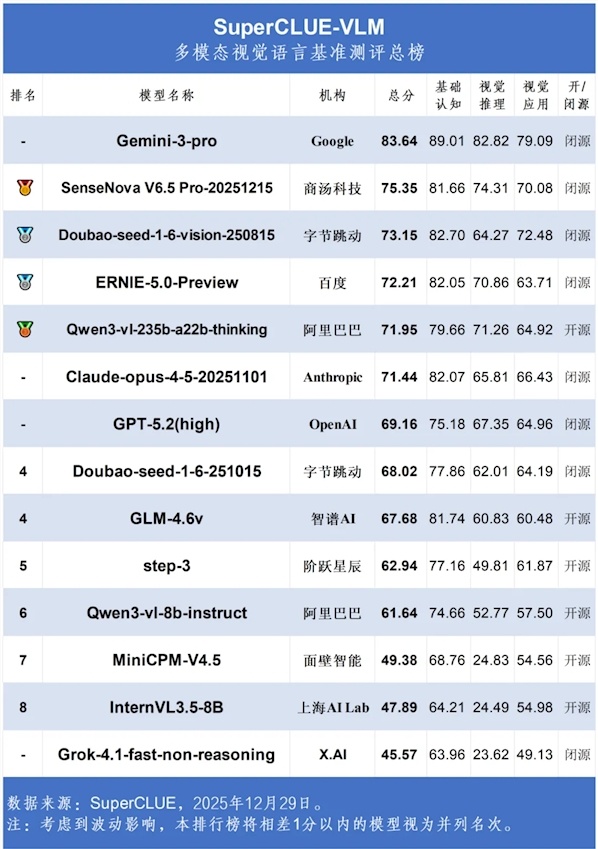


全球多模态大模型的竞争版图再次更新。近日,权威评测平台SuperCLUE-VLM发布2025年12月多模态视觉语言模型综合榜单,谷歌Gemini-3-Pro以83.64分实现断层领先,展现其在视觉理解与推理上的强势实力。字节跳动豆包大模型拿下73.15分挺进前三,商汤科技SenseNova V6.5Pro以75.35分位居第二。国产模型整体表现亮眼,体现中国AI在多模态赛道的加速追赶。
评测维度:三项能力全面检验模型“看图本领”
SuperCLUE-VLM从三大核心维度衡量模型的真实视觉理解水平:
– 基础认知:识别图片中的物体、文字、场景等基础元素;
– 视觉推理:理解图像中的逻辑关系、因果与隐含信息;
– 视觉应用:完成图文生成、跨模态问答、工具调用等任务。
Gemini-3-Pro全面领跑,国产模型加速追赶
谷歌Gemini-3-Pro在三项指标中均遥遥领先:
– 基础认知:89.01分
– 视觉推理:82.82分
– 视觉应用:79.09分
综合表现显著高于其他产品,进一步巩固了谷歌在多模态领域的领先地位。
国产阵营表现抢眼:
– 商汤SenseNova V6.5Pro以75.35分稳居第二,推理与应用能力较为均衡;
– 字节豆包大模型以73.15分排名第三,基础认知得分高达82.70,甚至超越部分国际模型,仅在视觉推理环节稍显不足;
– 百度ERNIE-5.0-Preview与阿里Qwen3-VL紧随其后,均跻身前五。
值得关注的是,Qwen3-VL成为榜单中首个总分突破70分的开源多模态模型,为全球开发者提供高性能、可商用的开放底座。

国际巨头表现分化:Claude稳健,GPT-5.2意外靠后
在国际阵营中,Anthropic的Claude-opus-4-5以71.44分位居中上游,延续其在语言理解方面的优势; 而OpenAI的GPT-5.2(high配置)仅获69.16分,排名相对靠后,也引发了业内对其多模态能力优化方向的讨论。
行业观察:多模态竞赛进入“实用化”新阶段
SuperCLUE-VLM榜单不仅是技术排名,更映射出行业趋势:
– 开源模型崛起:Qwen3-VL证明开源也能做到高性能,推动技术更广泛可及;
– 国产聚焦场景落地:豆包、商汤等模型在基础认知上优势明显,贴合中文互联网图文理解、短视频分析等高频需求;
– 视觉推理仍是难点:多数模型在复杂逻辑与因果推断等高阶任务上仍有差距,这也是Gemini保持领先的关键。
随着多模态能力成为AI Agent、智能座舱、AR/VR等下一代应用的核心支撑,这场“看图说话”的竞赛,正在决定谁能真正“看见”并理解世界。而中国大模型,已在迈向全球第一梯队的道路上加速奔跑。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?