

近日,YuanLab.ai 团队面向社区推出了源 Yuan3.0Flash 多模态基础大模型,并以开源形式发布,为 AI 领域带来新的机遇。该模型同时提供 16bit 与 4bit 模型权重,附带详尽的技术报告与训练方法,便于社区进行二次开发与行业定制,大幅推动 AI 技术落地。

Yuan3.0Flash 具备 40B 参数规模,采用创新的稀疏混合专家(MoE)架构,推理阶段仅激活约 3.7B 参数。此设计在提升推理准确性的同时,显著降低算力消耗,体现“更少算力、更高智能”的理念。此外,模型引入强化学习训练方法(RAPO),配合反思抑制奖励机制(RIRM),有效引导模型减少无效反思,进一步增强性能。
在架构层面,Yuan3.0Flash 由视觉编码器、语言主干网络与多模态对齐模块构成。语言主干引入局部过滤增强的 Attention 结构(LFA)与混合专家(MoE),在保障注意力精度的前提下,显著降低训练与推理的算力开销。视觉编码器可将视觉信号转为 token,与语言 token 一同输入,实现高效的跨模态特征对齐。
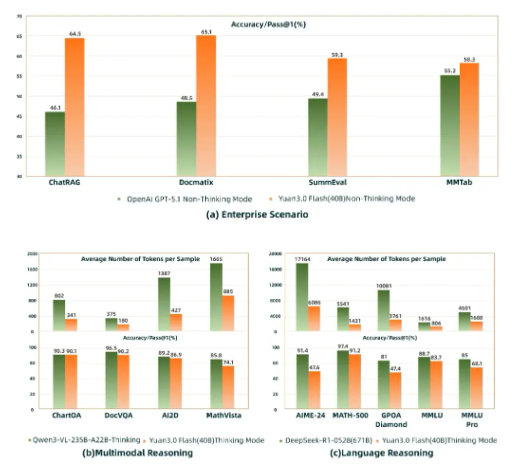
在实际应用中,Yuan3.0Flash 在企业场景表现已超越 GPT-5.1,尤其在 RAG(ChatRAG)、多模态检索(Docmatix)及多模态表格理解(MMTab)等任务上展现出显著优势。在多模态与语言推理评测中,其精度接近更大规模模型,如 Qwen3-VL235B-A22B(235B) 与 DeepSeek-R1-0528(671B),但 token 开销仅为后者的 1/4 到 1/2,显著降低企业大模型应用成本。
未来,源 Yuan3.0 将带来多个版本,包括 Flash、Pro 与 Ultra,参数规模覆盖 40B、200B 与 1T,为更多应用场景提供选择。
划重点:
🌟 Yuan3.0Flash 为开源的 40B 级多模态基础模型,提供多种权重与详尽技术资料。
💡 采用稀疏混合专家架构,在保证效果的同时显著降低推理算力,智能表现更优。
🚀 在企业应用中已超越 GPT-5.1,具备突出的多模态推理能力,显著降低使用成本。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?