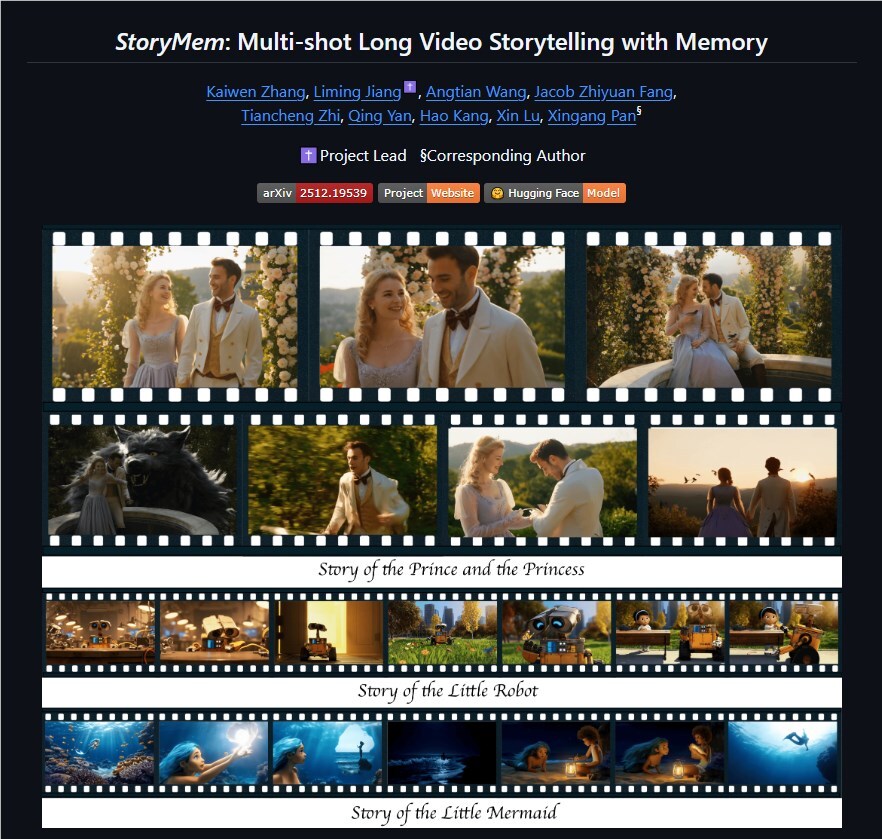


近期,字节跳动携手南洋理工大学发布的开源框架StoryMem在AI视频生成领域引起热议。该框架以“视觉记忆”为核心,将只会做单镜头的扩散模型改造成多镜头长视频的叙事引擎,能在几秒内自动生成时长超1分钟、包含多次镜头切换、角色和场景保持高度一致的连贯视频,被视为开源AI视频迈向电影化叙事的重要一步。
核心亮点:记忆机制驱动的逐镜生成
StoryMem的关键在于受人类记忆启发的“Memory-to-Video(M2V)”设计。系统维护一个紧凑、可动态更新的记忆库,存放已生成镜头中的语义关键帧。流程从文本到视频(T2V)模块开始,先生成第一个镜头并写入记忆;随后每生成新镜头,都会通过M2V LoRA把记忆中的关键帧注入扩散模型,使角色外形、场景风格和叙事逻辑在各镜头间始终一致。
当一轮生成结束后,框架会自动进行语义关键帧抽取与美学筛选,优化并更新记忆库。这样的迭代策略有效避免了传统长视频中常见的角色“变脸”和场景突变问题,同时只需轻量LoRA微调即可达成,无需海量长视频数据训练。

一致性显著提升,画面品质接近电影级
实验结果显示,StoryMem在跨镜头一致性上的表现明显优于现有方法,提升幅度可达29%,在人类主观评价中也更受青睐。同时,它保留了基础模型(如Wan2.2)的高画质、强提示遵循与镜头控制能力,支持自然转场与自定义故事生成。
项目还同步推出了ST-Bench基准数据集,涵盖300个多样化的多镜头叙事提示,用于更规范地评估长视频叙事质量。
应用广泛:快速预览与A/B测试好帮手
StoryMem尤其适合需要高效迭代视觉内容的场景:
– 营销与广告:从脚本快速生成动态分镜,便于多版本A/B测试
– 影视前期:辅助团队可视化故事板,降低概念阶段成本
– 短视频与独立创作:轻松产出连贯叙事短片,提升专业度与完成度
社区进展迅速:ComfyUI初步集成
发布后不久,社区便开始探索本地化部署,有开发者已在ComfyUI中搭建初步工作流,支持本地生成长视频,进一步降低上手门槛。
编辑观点:长视频的一致性一直是AI生成的难点。StoryMem以轻量且高效的方式切入并取得突破,显著推动开源视频模型向实用叙事工具演化。随着更多多模态能力的加入,其在广告、影视与内容创作中的潜力有望继续释放。
项目地址:https://github.com/Kevin-thu/StoryMem

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?