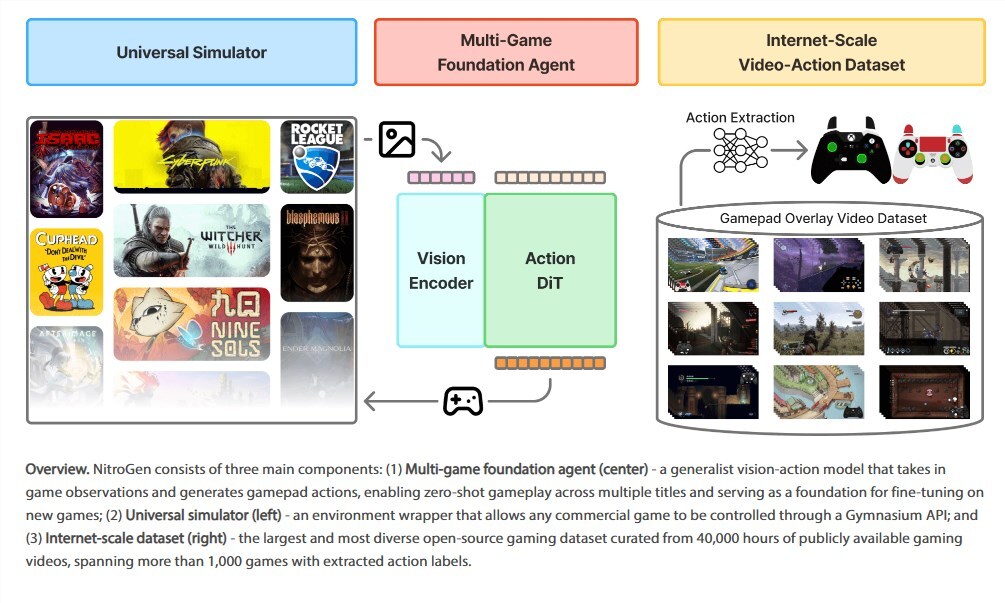


游戏AI迎来一次里程碑级进展。NVIDIA与斯坦福大学联合推出全新通用游戏智能体——NitroGen。该模型基于覆盖1000+款不同类型游戏、累计约4万小时的高质量游玩数据进行训练,展现出前所未有的跨游戏泛化与迁移能力。更值得一提的是,研究团队宣布全面开源训练数据集与模型权重,为全球AI与游戏研究社区提供强大基础设施。
“什么游戏都能玩”的通用智能体
NitroGen的目标是打破“一款游戏要训练一个模型”的老路。传统强化学习通常需要针对单一游戏从零开始训练;而NitroGen通过在海量且多样的游戏环境中学习(涵盖平台跳跃、策略、射击、解谜、模拟经营等类型),掌握通用的感知、决策与操作能力。实验结果显示,即使面对从未接触的新游戏,它也能快速上手,达到人类可玩水平。

项目地址:https://nitrogen.minedojo.org/
4万小时数据全开放,推动游戏AI普及
研究团队强调,NitroGen的表现不仅来自模型设计,更离不开高质量、规模化的数据。为此,他们同步发布了名为GameVerse-1K的数据集,包含:
– 1000+款商业与开源游戏的完整交互记录;
– 约4万小时的人类与AI游玩录像;
– 每帧画面、操作指令、奖励信号与状态元数据的精确对齐。
所有数据与模型权重将通过GitHub与Hugging Face开放,支持学术研究与非商业使用。
技术亮点:端到端视觉输入 + 统一动作空间
NitroGen采用纯视觉输入(原始像素),无需访问游戏内部API或状态,真正实现“像人类一样看画面来玩”。同时,它设计了统一的动作抽象层,把键盘、手柄、触屏等不同控制方式映射到标准化动作空间,让模型能够跨平台泛化。
行业意义:不仅是游戏,更是通用智能的试验场
业内普遍认为,NitroGen的意义远不止娱乐。游戏作为复杂、动态、维度高的模拟环境,是锻炼通用人工智能(AGI)的理想试验场。NitroGen验证的“多游戏大规模预训练 + 快速迁移”范式,未来有望延伸到机器人控制、自动驾驶、工业仿真等场景。
此次NVIDIA与斯坦福选择全面开源,不仅能加快科研迭代,也向行业传递出清晰信号:开放协作,是通往通用智能的最快路径。
目前,NitroGen代码与GameVerse-1K数据集已在官方仓库上线,开发者可立即下载体验。这场由游戏引燃的智能变革,正加速走向现实世界。

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?