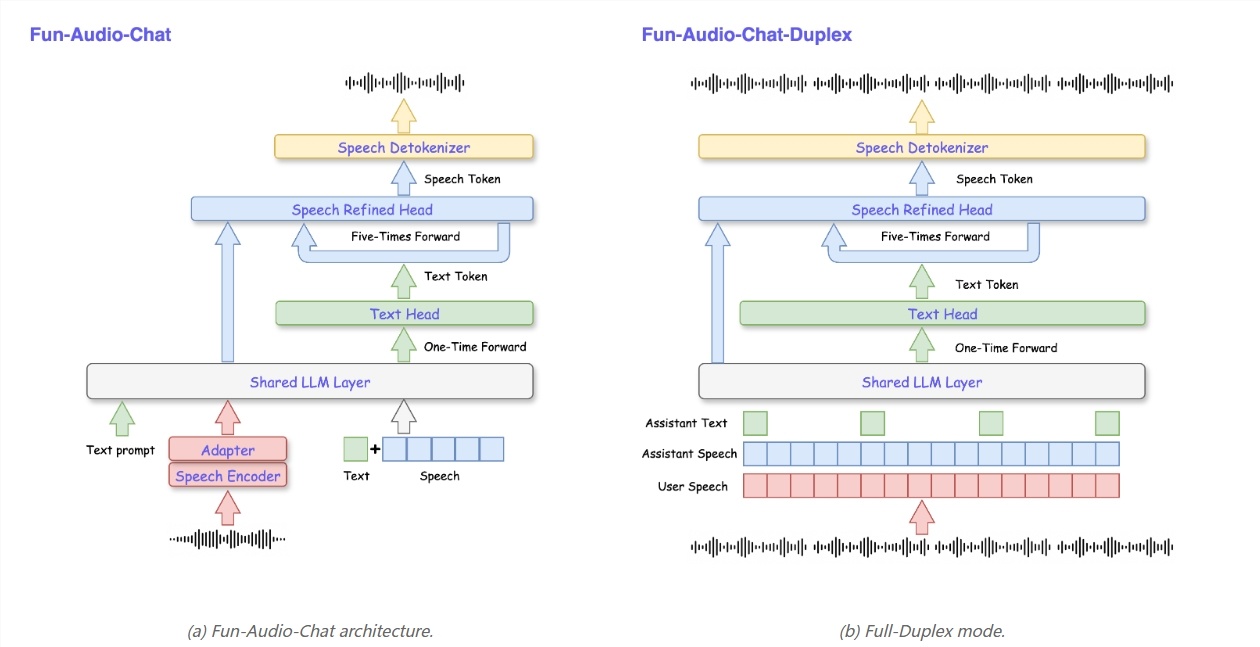


阿里巴巴通义实验室宣布开源新一代端到端语音交互模型Fun-Audio-Chat-8B。它主打超低延迟、自然流畅的语音交流,意味着开源语音AI进入新阶段。模型不仅能实时听懂用户说话,还具备强大的情绪感知能力,整体表现逼近GPT-4o Audio和Gemini 2.5 Pro。编辑独家解读:Fun-Audio-Chat并非普通聊天工具,更像一个真正的“AI语音伙伴”。

你只需开口说话,模型就能即时理解、思考,并用自然语音回应。告别传统ASR+LLM+TTS多模块串联带来的延迟,采用端到端的Speech-to-Speech(S2S)架构,对话体验更贴近真人交流。
核心技术亮点 超低延迟与高效设计:采用创新“双分辨率”架构(5Hz共享主干+25Hz精细头部),GPU计算资源可节省近50%,响应速度显著提升,更适合实时场景部署。
富有同理心的情感理解:模型能从语气、语速、停顿等细节识别用户情绪(如开心、疲惫或愤怒),即使没有明确说明,也能给出贴心、有共鸣的回复,让交互更有人情味。
强大语音函数调用:支持Voice Function Calling,用户用自然语音即可完成复杂操作,例如“帮我打开音乐”或“拨打电话”,真正实现“动口不动手”。

领先性能:在OpenAudioBench、MMAU、Speech-ACEBench、VStyle等多项国际权威评测中,Fun-Audio-Chat-8B在同尺寸模型里名列第一。综合能力超过GLM4-Voice、Kimi-Audio、Baichuan-Omni等开源产品,部分指标已能媲美或领先闭源顶级模型。
丰富应用能力 能实时回答语音问题(例如概括一段语音内容);
可准确识别情绪、音色与指令;
支持多语言翻译与角色扮演;
能模拟多种情感语音输出(如温柔、严肃、开心);
适用于情感陪伴、智能设备控制、语音客服等场景。
编辑观点:本次开源包含完整8B模型权重、推理代码和Function Call示例,大幅降低开发门槛,推动语音AI生态加速发展。感兴趣的开发者可前往GitHub、Hugging Face或ModelScope下载体验,开启属于你的“高情商”语音AI时代!
项目地址:https://funaudiollm.github.io/funaudiochat/

















用户38505528 9个月前0
粘贴不了啊用户12648782 10个月前0
用法杂不对呢?yfarer 10个月前0
草稿id无法下载,是什么问题?